滚滚长江东逝水,浪花淘尽英雄。是非成败转头空。青山依旧在,几度夕阳红。—— 《临江仙》
电脑店
从前,有一家电脑店。原来你即是老板,又是店员时,拿到清单,你就必须亲自动手采购,然后一个个零件组装。每天都做着即重复又辛苦的活。
虽说你的组装技术已经很娴熟了,但是偶尔还发生装错的情况(大概是那天和老板娘吵架了),把一个客人要求的 CPU i5 装成了 CPU i7。结果是你亏本或者赚得少了。

后来,你采购了一个自动组装电脑的机器人。你只要告诉它电脑的配置,并把零件放到指定的箱子中。接着启动这台机器,它就自动帮你组装好电脑了。它每天都干重复的活也不会叫辛苦。
最重要的是准确,它不会因为心情不好,而装错。因为它根本不会闹情绪。
这样,老板就可以从重复的工作解放出来。然后将多出来的时间花在与人的沟通上,为有不同需求的人设计更合适的电脑配置清单。毕竟游戏发烧友和办公小白领的需求是不一样的。
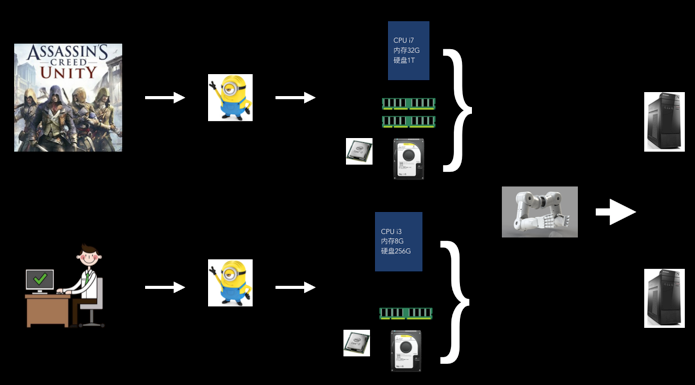
在运维领域,不少运维人都干着即是老板又是店员的工作。如果在运维领域也能有这样的“机器人”该多好。事实上,Ansible、Puppet、Check 就是这样的机器人。
为什么要从零设计一个运维机器人
本文并不想生硬地罗列 Ansible 的各个知识点。因为那样,大家不如直接看 Ansible 官方文档就好。
笔者采用从零设计一个运维机器人的方式来告诉你,为什么 Ansible 会是现在这个样子。当然,现实中的 Ansible 不会像本文所写的那样一步步设计。
为什么要这样呢?因为笔者觉得只有知道一个工具背后的设计原理,真正用这个工具才会得心应手。
运维机器人的最终模样
首先,需要确定一下实现这个运维机器人的目的是什么。我们并不是希望所有的运维工作都交给运维机器人,而是希望运维工作中重复的那部分尽可能的交给机器人,把创造性的工作全部交给人。如下图所示。

以终为始是一种非常有效的实现目标的思考模型。根据此思考模型,我们首先必须探讨运维机器人的最终模样。然后,再讨论可能的解决方案。
那么,什么样的运维机器人能帮助我们实现上述的自动化运维目标呢?想像一下。是不是只要我们对着运维机器人说一句:“我要部署一个 Nginx 到 192.168.12.11”。它就可以帮我们完成了?
但是它怎么知道如何连接到 192.168.12.11 呢?是使用用户名密码的方式,还是使用私钥?它又怎么知道 Nginx 需要什么样的配置呢?一问下来,其实,语音运维只适用于启动一些预定义的动作。就像汽车的一键启动。你不可能使用语音来对 Nginx 进行大量的配置。
而纯文本才是进行大量配置的最好媒介。
所以,运维机器人的最终模样是:我们将部署的主机 IP、登录方式、Nginx 的配置放在一个文本文件中,然后运维机器人读取这个文本文件,然后根据配置进行部署。如果部署的是业务系统,我们还需要准备该业务系统的二进制包。如下图所示。
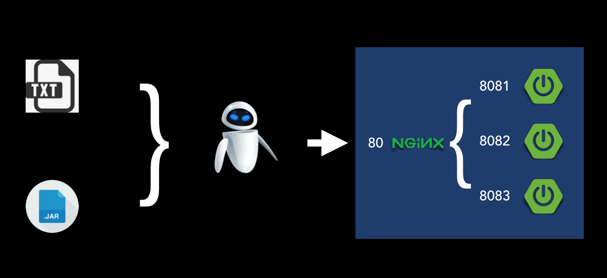
那么,我们在文本文件中使用何种语言描述我们的配置需求呢?可以分成两种。一种是利于人类学习的自然语言(如英语)。另一种是利于机器读取的结构化数据(如YAML、JSON)。
按当前的技术实现的可能性,不论是运维机器人,还是交给其它程序,都需要将自然语言转到结构化的数据。就像程序员,需要将业务知识翻译成编程语言;像编译器将编程语言翻译成机器真正能识别的二进制代码。
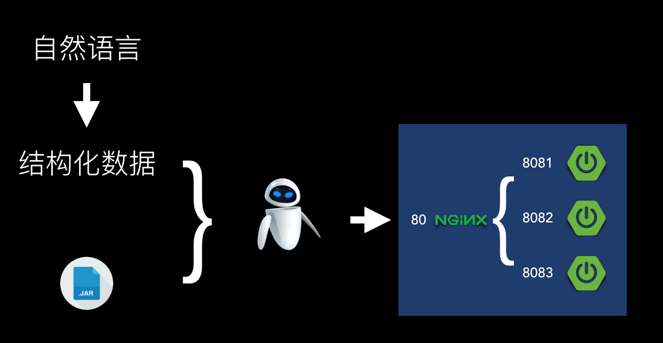
运维机器人的真正核心不是将自然语言转成结构化的数据。所以,文本文件中,我们直接写结构化数据。同时,我们决定使用 YAML 格式作为结构化数据的载体。因为它是非常流行的配置文件格式。降低人们写结构化数据的难度。
当然,好的设计不应该与具体配置文件格式耦合。
实现运维机器人要解决哪些问题
以上只是确定了运维机器人的最终模样及使用方式,解决的是用户的问题。但是因为我们是运维机器人的设计者,我们必须考虑如何实现它。
回想一下,平时我们的运维人员是如何实现自动化的?是不是写好了 bash 脚本后,然后将脚本上传到目标机器,最后在目标机器上执行该脚本。
这个 bash 脚本其实也可以算是一种结构化的数据格式,而且是一种不需要再做编译,目标机器能直接运行的格式。
在平时的自动化方式基础上进行抽象。我们觉得要实现运维机器人要解决的关键问题有:
- 需要将 YAML 转成目标机器可执行的程序(或脚本)。
- 需要将可执行的程序上传到目标机器,并执行。
为什么一定要将 YAML 转成目标机器可执行的程序呢?直接写 bash 不就可以了?
因为运维机器人要解决的不止是 Linux 系统的自动化运维,还有 Windows,甚至路由器的。所以,我们需要使用一种独立于目标机器的语言来描述我们的运维需求。
问题 2 我们先放一放,因为上传代码到目标不是运维机器人的关键问题。
实现 YAML 转成 ?
虽然咱们希望运维机器人能运维所有类型的机器,但是本文重点不是要在一篇文章内实现所有类型机器的自动化运维。接下我们只针对 Linux 机器进行讲解。
现在我们遇到的问题是要将 YAML 转成什么程序以实现在目标机器上执行?
如果我们将 YAML 转成 Java 程序,那么目标机器就必须装有 JDK,这是不现实的。你不可能让所有的 Linux 机器都安装 JDK。所以,YAML 最好是能转成所有 Linux 都支持程序。目前笔者能想到的就是:bash 和 Python。
P.S. 现实中,很多运维工具要求所有的目标机器必须安装特定的客户端的。而 Ansible 却不需要。如果在使用自动化运维工具前,你要为所有的机器安装特定的客户端,那么,你怎么自动化为所有的机器自动安装客户端呢?留着读者思考。
从 bash 和 Python 之间做选择,没有什么好讨论的,选择 Python。
那么,怎么将 YAML 转成 Python 代码呢?这要看我们怎么设计 YAML 内的描述语言了。其实就是设计自动化运维机器人的领域特定语言(DSL)。为方便讨论,我们称之为:OPL 语言。
OPL 语言1.0:基本要素
现在咱们在为一台机器部署一个 Nginx 作为切入点,来设计我们的 OPL 语言。以下就是1.0版本:
---
- host: "192.168.35.10"
ansible_ssh_user: vagrant
ansible_ssh_pass: vagrant
tasks:
- name: install nginx
yum:
name: nginx
action: install
- host:代表部署的目标机器。
- ansible_ssh_*:开头的 key 是指定 ssh 连接的用户名和密码。
- tasks:是一个数组,包含一系列任务。
- name:任务名称,方便人阅读。
- yum:要执行的任务的类型,也就是要执行 yum 操作。yum 任务下的 name 属性代表要安装的软件名称,action 属性代表执行的是安装操作。
1.0版的 OPL 语言包含了运维领域最基本要素:
- 目标主机的描述
- 连接目标主机的必要信息
- 任务描述
为方便沟通,我们暂将些 YAML 文件命名为 playbook.yml。
OPL 语言2.0:采用声明式的任务描述方式
注意到 OPL 语言1.0中的任务描述方式很像现实中执行shell:yum install nginx。我们称这种方式为脚本式的。脚本式的描述方式与传统的运维方式更像。
但是声明式的描述方式更适合 OPL 语言所要解决的问题。我们期望的是描述我们期望的结果,而不是换一种方式写脚本。
采用声明式的描述方式,还有一个很重要的原因:幂等的。在概念上,声明式的描述被执行了多少次,结果都应该是我们所声明的。而第二次执行脚本式的代码时,你会问,结果还会和我第一次执行的一样吗?
所以,2.0中,任务描述方式改成声明式:
- name: Ensure nginx present
yum:
name: nginx
state: present
state 属性的值为 present 形容词。
P.S. 识别声明式与脚本式的简单办法是看它在描述目标状态时,是用动词,还是用形容词。
除了 yum 任务,接下来要实现的所有任务也将采用声明式。
OPL 语言3.0:主机清单
在 2.0 版本中,我们只实现了一台目标机器的部署。但是现实中,我们常常要针对多主机进行部署。我们需要一种更好的方式去描述目标主机。
主机清单的内容,也需要一个文件来存放。关于文件的格式,我们采用一种类 INI (INI-like)的格式。文件名暂命名为:inventory。以下是 inventory 文件的内容:
[nginx]
192.168.35.10
192.168.35.11
192.168.35.12
[springboot]
192.168.35.20
192.168.35.21
192.168.35.22
[] 括号中是主机分组的名称,接下来是就是这个组内目标机器的 IP 列表。
而上一版本中的 playbook.yml 中的 host key 是单数,所以不合适了。我们改成 hosts 复数,同时值变成了在主机清单中的组名,而不是具体某台主机的 IP。
playbook.yml 文件内容如下:
- hosts: "nginx"
ansible_ssh_user: vagrant
ansible_ssh_pass: vagrant
tasks:
- name: install nginx
yum:
name: nginx
state: present
细心的读者朋友应该发现了,目标机器的连接方式是各不相同的,有些用用户密码的方式,有些用密钥的方式。所以,我们再将 ansible_ssh_* 写在 playbook.yml 中已经不合适了。
笔者只能告诉你,这是剧情需要。OPL 语言的后续版本会解决此问题。
现在咱们为运维机器人准备的内容已经不再只是一个 playbook.yml 文件,它应该是一个目录了,目录内容如下:
├── inventory
└── playbook.yml
OPL 语言4.0:include 任务
在 OPL 1.0 版本,已经考虑到了一次部署将会包括很多子任务。所以使用了 tasks 这个复数词。
而现实中一次部署任务往往包含几十个子任务,playbook.yml 的文件内容一定会膨胀。这样的源代码非常难维护。所以,在 4.0 版本,我们决定为 OPL 增加一个 include_tasks 任务类型。用户可以通过 include_tasks 任务类型将另一个包含任务描述的文件(这里我们称为子任务集)引入到当前的 playbook.yml。
- hosts: "nginx"
tasks:
- name: config firewalld
include_tasks: firewalld.yml
- name: install and config nginx
include_tasks: nginx.yml
这时的目录结构如下:
├── firewalld.yml
├── inventory
├── nginx.yml
└── playbook.yml
所有的子任务文件都与 playbook.yml 同级,会显得很乱,不利于区分哪个文件是 OPL 的执行入口。我们是不是可以建了一个 tasks 目录来专门存放呢?事实上就应该这么做。
所以,经过重构,得到了4.1 版本。目录结构调整如下:
├── inventory
├── playbook.yml
└── tasks
├── firewalld.yml
└── nginx.yml
playbook.yml 中 include_tasks 任务的文件路径做相应的调整,改成:
- name: install and config nginx
include_tasks: tasks/nginx.yml
OPL 语言5.0:丰富任务类型
5.0 之前的版本,已经实现了一个基本框架。5.0 版本中我们希望加入更多的任务类型,以满足不同的运维需求。
copy 任务
部署过程中,常常需要将一些文件从本地 copy 到目标机器。copy 任务的代码样例如下:
- name: "ensure nginx package exists"
copy:
src: "./files/nginx.tar.gz"
dest: "/tmp"
为方便管理,我们将所有 copy 任务用到的文件放在 files 目录中。此时目录结构调整如下:
├── inventory
├── playbook.yml
└── tasks
├── files
│ └── nginx.tar.gz
├── firewalld.yml
└── nginx.yml
file 任务
设置文件夹的权限是非常常见的操作,所以就有了 file 任务。
- name: "ensure folder /app/nginx is created"
file:
path: "/app/nginx"
owner: "nginx"
group: "nginx"
mode: "0700"
state: "directory"
- owner:指定文件的所属用户。
- group:指定文件的所属用户组。
- state 属性的值可以为:
- absent:不存在。可以理解为删除该文件或文件夹。
- directory:文件夹。如果该文件夹不存在,则创建。
- file:文件。如果不存在,则创建。
- touch:与 linux 的 touch 实现相同的效果。
service 任务
在服务安装完成后,最常用的操作就是启动服务了。同时,它会根据不同的操作决定使用何种 service 实现。支持:BSD init, OpenRC, SysV, Solaris SMF, systemd, upstart。这就是封装的强大。用户只需要描述他的期望,剩下的机器能解决的,都由机器解决。
- name: ensure svn service started
service:
name: svnserver
state: started
enabled: true
enabled 属性值为 true 代表开机自动启动。state 属性值可以为:
- reloaded:服务是被重新加载过的。
- restarted:服务是被重启过的。
- started:服务是启动的。
- stopped:服务是停止的。
小结
如果 OPL 语言设计得足够好,它应该可以轻松地进行扩展。此处举的几个例子已经达到目的,就不再举更多的例子。
P.S. OPL 语言的子任务在 Ansible 中称为模块(module)。
OPL 语言6.0:模块化任务
在 5.0 版本中,我们为 OPL 增加了一些的任务类型。在写了一段时间 OPL 语言后,发现采用 include_tasks 对大规模 playbook.yml 进行拆分的方式,设计上的存在不足:不够内聚。具体表现如下:
- include_tasks 任务不利于分享给其他人使用。
- nginx.yml 中的 copy 任务中,我们约定从 files 目录中读取文件。但是其它子任务中的 copy 又从哪里读取文件呢?这就是子任务之间会相互影响。
那么如何让子任务更内聚呢?将“子任务”的集合进行封装,并命名为 role。这样每个 role 都被看作成一个模块。
目录结构调整为:
├── inventory
├── playbook.yml
└── roles ## 存放 playbook 使用到的 role
├── firewalld
│ ├── files
│ └── tasks
│ └── main.yml
└── nginx
├── files
│ └── nginx.tar.gz
└── tasks
└── main.yml
playbook.yml 内容调整如下:
- hosts: "nginx"
ansible_ssh_user: vagrant
ansible_ssh_pass: vagrant
roles:
- firewalld
- nginx
每个 role 只需要管理自己内部的逻辑,比如,每个 role 都会有一个 files 目录。copy 任务默认从所在 role 目录中的 files 目录中读取。上文介绍的 copy 任务(注意 src 属性值)改为:
- name: "ensure nginx package exists"
copy:
src: "nginx.tar.gz"
dest: "/tmp"
今后设计的所有任务类型默认都从 role 自身目录开始。
每个 role 的执行入口约定为 tasks/main.yml。include_tasks 任务仍然可以使用,只不过,默认从 main.yml 同级目录获取子任务集合。比如 nginx/tasks/main.yml 包含任务:
- name: "Config nginx"
includes_tasks: config.yml
nginx role 的 tasks 目录内容如下:
└── nginx
├── files
│ └── nginx.tar.gz
└── tasks
├── config.yml
└── main.yml
OPL 语言7.0:支持变量
6.0 版本中,我们如何将 role 分享给其他人使用呢?目前能想到的成本最低的方式是直接将 role 目录拷贝一份,并 push 到 GitHub 上。其他人将 role 下载到自己的 roles 目录即可。
可是,其他人下载 role 后,也需要查看 role 的内部逻辑,然后修改其中的逻辑,才能为自己所用。因为并不是每个人的 nginx 配置都是一样的。这说明咱们当的 OPL 的设计违反了程序设计的开闭原则:
开闭原则规定“软件中的对象(类,模块,函数等等)应该对于扩展是开放的,但是对于修改是封闭的”,这意味着一个实体是允许在不改变它的源代码的前提下变更它的行为。 —— 维基百科
那如何设计才能符合开闭原则呢?方法是将经常变化的与基本不用变化的逻辑分离。
以上文中的 nginx role 为例讲解。nginx 的安装部署,整个过程对于所有人来说都是大体相同的。不相同的是 nginx 的配置。
OPL 语言7.0版本将这些“配置”抽象出来,也就是变量。role 根据自身需要在 role 内部定义变量,用户在 role 外部可重新设置变量的值,即可定义 role 中的变化的部分。比如重新定义 nginx 的配置。
那么,具体如何定义及使用变量呢?
区分默认变量和用户定义变量
对于“具体如何定义及使用变量呢”的问题,我们第一步是要将默认变量和用户定义变量区分开。
以上文的 copy 子任务为例:
- name: "ensure nginx package exists"
copy:
src: "nginx.tar.gz"
dest: "/tmp"
copy 的目的地的属性为 dest,它的值是“写死”的。但是并不是所有人都希望 copy 到 /tmp 目录。/tmp 目录是 role 本身的默认值,如果用户不满意这个默认值,可以在使用 role 时,修改 dest 的值。
这又引出另一个问题:role 内部如何定义默认值?
在 role 目录下,我们新建一个 defaults 目录,并放一个 main.yml 。defaults/main.yml 文件内容定义变量的默认值。role 的目录结构调整为:
├── defaults
│ └── main.yml
├── files
│ └── nginx.tar.gz
└── tasks
├── config.yml
└── main.yml
nginx/defaults/main.yml 的内容如下:
{% raw %}
---
nginx_package_tmp_dir: "/tmp"
# 其它变量,此处省略
copy 子任务的描述改成:
- name: "ensure nginx package exists"
copy:
src: "nginx.tar.gz"
dest: "{{ nginx_package_tmp_dir }}"
{{ }} 是变量的占位符。nginx_package_tmp_dir 会被实际值所替换。
{% endraw %}
template 子任务
nginx 的配置是一个 nginx.conf 文件。nginx role 中的 nginx.conf 应该是一个模板,模板内的变量占位符会被变量实际值替换。模板引擎我们选择:Jinja2,一个 Python 的模板引擎。
这样想来,我们需要一个新的子任务类型 template:
- name: ensure nginx config
template:
src: "nginx.conf"
dest: "/usr/local/nginx/conf/nginx.conf"
# 目标路径
与 copy 任务类似,从哪里拿 nginx.conf 模板文件呢?为区分模板文件与一般文件,我们在 role 目录下创建一个 templates 目录。最终 nginx role 的目录结构看起来是这样的:
├── defaults
│ └── main.yml
├── files
│ └── nginx.tar.gz
├── tasks
│ ├── config.yml
│ └── main.yml
└── templates
└── nginx.conf
nginx.conf 部分内容如下:
## 省略
server {
location / {
proxy_pass http://127.0.0.1:{{apps_port}}/;
}
}
{% raw %}
文件中 {{apps_port}} 最终会被实际变量的值替换。
{% endraw %}
在哪里定义变量?
目前所有的默认变量值都定义在 defaults/main.yml 中,那么,role 的使用者如何定义自己的变量值呢?
我们支持多种方式:
-
playbook.yml 文件中 playbook.yml 文件中,又分为两种情况:1. 在 roles 级别;2. 在 playbook 级别的。代码样例如下:
--- - hosts: "nginx" ## 1. playbook 级别变量 vars: apps_port: 9090 roles: - firewalld ## 2. roles 级别变量 - { role: nginx, apps_port: 9091 } -
inventory 文件中 针对每台机器,同一变量可能需要设置成不同的值。
[springboot] 192.168.35.20 apps_port=9091 ansible_ssh_user=vagrant ansible_ssh_pass=vagrant 192.168.35.21 apps_port=9092 ansible_ssh_user=vagrant1 ansible_ssh_pass=vagrant1 192.168.35.22 apps_port=9093 ansible_ssh_user=vagrant2 ansible_ssh_pass=vagrant2
在 OPL3.0 版本中的遗留问题,终于解决了。ansible_ssh_* 类的变量可以关联到具体某台机器了。也就是每台主机的 ansible_ssh_* 的值都可以是不一样的。
-
命令行转入 在命令行中加入参数:
--extra-vars即可。ansible-playbook release.yml --extra-vars "version=1.23.45 other_variable=foo"
当变量可以在多处定义时,随之而来的就是变量的优先级问题。变量的优先级应该如何设计呢?问题留给读者思考。
OPL 语言8.0:支持条件判断
8.0 版本决定加入条件判断:when。用法如下:
- name: Ensure nginx exists
yum:
name: nginx
state: present
when: ansible_os_family == "CentOS"
当目标机器不是 CentOS 时,执行 yum 操作一定是失败的。所以,只有 ansible_os_family == "CentOS" 为 true 时才执行该子任务。
上例中,只是单条件。如果多条件呢?如何实现“与”和“或”呢?
“与”的示例如下:
- name: "shut down CentOS 6 and Debian 7 systems"
command: /sbin/shutdown -t now
when: ansible_distribution == "CentOS" and ansible_distribution_major_version == "6"
注:command 是一个执行命令的子任务类型。
“与”还有另一种写法:
- name: "shut down CentOS 6 systems"
command: /sbin/shutdown -t now
when:
- ansible_distribution == "CentOS"
- ansible_distribution_major_version == "6"
“或”的示例如下:
- name: "shut down CentOS 6 and Debian 7 systems"
command: /sbin/shutdown -t now
when: ansible_distribution == "CentOS" or ansible_distribution == "Debian" )
当然,你可以结合“与”和“或”来使用:
- name: "shut down CentOS 6 and Debian 7 systems"
command: /sbin/shutdown -t now
when: (ansible_distribution == "CentOS" and ansible_distribution_major_version == "6") or
(ansible_distribution == "Debian" and ansible_distribution_major_version == "7")
你可以把 when 想像成编程语言中的 if语句。它与具体的子任务的类型无关,任务子类型下都可以使用 when。
OPL 语言8.1:支持遍历
当某个任务需要根据数组中的数据进行重复执行时,OPL 语言就要考虑支持遍历了。 {% raw %}
- name: Ensure soft exists
yum:
name: "{{ item }}"
state: present
when: ansible_os_family == "CentOS"
with_items:
- gcc
- gcc-c++
可以将 with_items 理解成编程语言中的 for语句。{{ item }} 中的 item 约定代表遍历的元素。
{% endraw %}
OPL 语言9.0:子任务支持返回值
用户在使用 OPL 语言时,写出以下代码:
- name: ensure nginx config
template:
src: "nginx.conf"
dest: "/usr/local/nginx/conf"
- name: restart nginx
service:
name: nginx
state: restarted
代码问题出现在哪里呢?它不是幂等的。不论 nginx.conf 文件是否有更新,每执行一次 OPL 它都会重启一次 nginx 服务。
我们期望的是当 nginx.conf 有更新时才执行启动 nginx 服务。
我们应该如何设计 OPL 以规避此类问题呢?
我们从问题本身开始。当子任务设计完成后,我们需要根据子任务的执行结果去执行另一个子任务。用通用编程语言来表达,很简单:
boolean changed = template("nginx.conf", "/usr/local/nginx/conf")
if(changed){
service("nginx","restarted")
}
在通用编程语言中,我们很容易就实现的功能,在 YAML 中如何实现呢?其实类似的,让所有的子任务支持返回值,然后在后续子任务做判断就好了。代码如下:
- name: ensure nginx config
template:
src: "nginx.conf"
dest: "/usr/local/nginx/conf"
register: nginx_config_result
- name: restart nginx
service:
name: nginx
state: restarted
when: nginx_config_result.changed
register 是新的语句,用于定义子任务返回结果名称。nginx_config_result 是一个对象,其中 changed 就是它的属性。changed 为 true 时,代表 ensure nginx config 子任务有变化。
OPL 语言9.1:支持延迟处理
在使用 9.0 版本一段时间后,用户开始报怨以下代码写起来太哆嗦,而且容易出错:
- name: ensure nginx config
template:
src: "nginx.conf"
dest: "/usr/local/nginx/conf"
register: nginx_conf_result
- name: ensure nginx upstream config
template:
src: "upstream.conf"
dest: "/usr/local/nginx/conf/upstream.conf"
register: nginx_upstream_result
- name: ensure nginx vhosts config
template:
src: "vhosts.conf"
dest: "/usr/local/nginx/conf/vhosts.conf"
register: nginx_vhosts_result
- name: restarted nginx service
service:
name: nginx
state: restarted
when: nginx_conf_result.changed or nginx_upstream_result.changed or nginx_vhosts_result.changed
用户写成这么哆嗦的语句,并不是用户的问题。而是我们的设计有没考虑到的地方。也就是有些任务是需要被另外一些任务触发执行的。我们当前不支持此种场景。
为实现此类场景,需要做两件事情:
- 主动触发子任务,使用
notify语句指定要触发的另一个任务的任务名。 - 集中保存被动触发的任务,以区分主动执行的任务和被动执行的任务。约定被动触发的任务放在 role 目录下的 handlers/main.yml 文件。
接下来,我们具体看下如何重构以上哆嗦的写法。
第一步,对 nginx role 目录进行调整:
├── defaults
│ └── main.yml
├── files
│ └── nginx.tar.gz
├── handlers
│ └── main.yml
├── tasks
│ ├── config.yml
│ └── main.yml
└── templates
└── nginx.conf
第二步,重构 tasks/config.yml:
- name: ensure nginx config
template:
src: "nginx.conf"
dest: "/usr/local/nginx/conf"
notify:
- restart nginx
- name: ensure nginx upstream config
template:
src: "upstream.conf"
dest: "/usr/local/nginx/conf/upstream.conf"
notify:
- restart nginx
- name: ensure nginx vhosts config
template:
src: "vhosts.conf"
dest: "/usr/local/nginx/conf/vhosts.conf"
notify:
- restart nginx
第三步,向 handlers/main.yml 文件加入被动执行的任务:
---
- name: restart nginx
service:
name: nginx
state: restarted
OPL 语言之后
以上只是 OPL 语言的雏形,我们还需要根据现实的情况不断的扩展和完善。OPL 语言的设计只是实现运维机器人的一部分工作。我们还需要做的工作包括:实现一个程序,它会对 OPL 语言进行编译。并将编译后的 python 脚本上传到目标服务器。python 脚本运行后,这个程序将运行结果反馈给用户。
这个程序就是我们在命令行中敲入的 ansible-playbook 了。
至于 ansible-playbook 的更多细节,已不属于本文的内容,不作讨论。
总结
本文首先从电脑店引出现代自动化运维工具的基本模型。接着讨论应该如何设计一款自动化运维工具(上文称为运维机器人)。从而得知需要解决两个关键问题:1. 需要将 YAML 转成目标机器可执行的程序(或脚本);2. 需要将可执行的程序上传到目标机器,并执行。然后我们花了大篇幅介绍 OPL 语言的设计(实际上是介绍 Ansible 的 YAML 为什么要像现在这样写)。最后简单介绍 OPL 语言后要做的事情。
老实说,以上并不是真正意义上的从零设计 Ansible。也不存在什么 OPL 语言。笔者只是希望通过 OPL 语言的设计过程,尝试让读者了解 Ansible 的设计思路。期望读者因为本文,学习 Ansible 变得更轻松。
最后,文末有 OPL 语言各版本的样例。
附
- 从零设计 Ansible 代码样例:https://github.com/zacker330/design-ansible
- Jinja2 模板语言:http://docs.jinkan.org/docs/jinja2/
Last modified on 2019-09-19