There’s a popular idea in the testing world called precise testing (精准测试). In short, it is the ability to run only the tests affected by a change, instead of running the entire suite every time.
I think the idea is right — but the way our industry usually implements it is wrong. In this post I’ll first explain what precise testing is and why the mainstream approach is heading in the wrong direction, and then show a different path: precise testing turns out to be nothing more than a byproduct of incremental builds.
How the industry defines precise testing
A few definitions float around (translated from Chinese-industry sources; skip ahead if you already know them):
From Chen Yiqing of NetEase (2020):
A process that uses certain techniques and auxiliary algorithms to visualize, analyze, and optimize the traditional software testing process, making testing more visual, intelligent, trustworthy, and precise. (source)
From Qi Lei, a testing consultant at HSBC (2021):
Put simply: it’s based on source-code change analysis, combined with analysis algorithms, to determine the scope of impact and improve testing efficiency. (source)
From Nebula Testing (2022):
Precise testing in one sentence: the traceability between test cases and code. That is its most essential nature. (source)
From Dewu Tech (2023):
Precise testing is based on source-code change analysis combined with analysis algorithms to determine the scope of code affected by a change, then designing targeted test cases. On one hand it improves testing efficiency; on the other, it establishes a logical mapping between test cases and program code — captured by tooling that collects the code paths and test data executed during testing. These are the two cores of precise testing: forward tracing and reverse tracing. (source)
Here is an architecture diagram from NetEase Yanxuan, a Chinese e-commerce platform, illustrating a typical precise-testing platform:
My own definition
To me, precise testing should be defined like this: it is the ability to test only what changed, rather than running a full test suite for every change. Note that I say “change,” not “code change” — I mean every kind of change, including manual ones.
The idea is not complicated. It’s three steps:
- Find the change.
- From the change, find the related test cases.
- Run only those related test cases.
Honestly, a more accurate name would be incremental testing — you are, after all, testing against an incremental change. And if you can already run just the one test you want to run, isn’t that precise testing too?
The mainstream implementation
Step 1: Find the code change
Diff between commits.
Step 2: Map the code change to related test cases
To “find the test cases related to a code change,” you must know the relationship between code and test cases. The usual way to capture that relationship is to do the following while running the tests:
- Record the traffic.
- Record the call chain of the code executed by that traffic.
- Record the relationship between each test case’s metadata and that call chain.
This builds the mapping between the invoked code and the test cases. And because in reality plenty of code isn’t covered by any test, static code analysis is combined with coverage measurement to generate a report of the untested code.
You can see that building “the relationship between code and test cases” this way is extremely expensive. That’s why this field spawns whole platforms: traffic-replay platforms, test-case management platforms, precise-testing platforms, and so on. It also leaves everyone with the impression that you need a platform first before you can do precise testing.
At bottom, it’s instrumentation: reconstruct the code’s execution path and find the corresponding test cases. And most of what you’ll find online only implements this for Java or C++ — I haven’t seen it done for other languages.
Step 3: Run only the related test cases
Once you have the code-to-test mapping, this part is easy.
The pitfalls of the mainstream approach
Here are the problems Qi Lei summarized about precise testing:
- Building the mapping for manual testing is complicated; if requirements change frequently, maintaining the cases and their relationships costs enormous time and energy.
- Precise testing needs a certain amount of automated test coverage to be meaningful (e.g. API automation). If you have too few cases and weak code-to-case links, changing code may not yield any useful result.
- You really want a case-management system to help build the relationship with the code.
- You need strong QA/SDET engineers to build the whole system. But in the long run, embedding precise testing into the company-wide quality platform is an improvement for both new and maintenance projects.
- The project lifecycle needs to be fairly long; spending huge effort building and maintaining the whole system for a short-term project isn’t worth it. Short projects can instead just monitor API test coverage across iterations.
I think Qi Lei’s summary is correct — these really are pitfalls. But they are not the pitfalls of precise testing; they are the pitfalls of the mainstream way of implementing it. To put it bluntly: it’s like drinking water from the wrong angle.
Why the mainstream approach is wrong in direction
Why do I blame the implementation? Here are my arguments — corrections welcome.
It’s limited to a single language
Precise testing should not target only code changes — it should target all changes. And not only changes in a single language, but changes in any language.
The definition of precise testing isn’t bound to one language; it’s about every change in a software project. When a SQL statement changes, don’t you want to know precisely which tests to run? When a piece of front-end CSS changes, don’t you want to know precisely which tests to run?
The mainstream approach is designed only for single-language scenarios. The same idea simply can’t scale to multiple languages — and I mean multiple languages within one project, not separate single-language projects.
You can only do it on a platform
That is, you first need a platform before you can do precise testing. But what we actually want is to do precise testing right in the developer’s local environment.
So what’s the right direction?
The title isn’t saying precise testing itself is a mistake — it’s saying the implementation above is the wrong method. So what is the right direction?
The answer is incremental builds. Before I can explain, I need to talk about incremental builds and Bazel.
Full builds vs. incremental builds
In the build world there are two kinds of builds:
- A full build builds all the code in the repository.
- An incremental build rebuilds only the changed code and the code affected by that change.
By definition, what an incremental build does and what precise testing does are nearly identical. The only difference is swapping the build command for the test command.
This is exactly why I think “precise testing” should really be called “incremental testing.”
Today, in the incremental-build space, Bazel is the standout.
A quick intro to Bazel
Bazel is a build tool Google open-sourced in 2015. It defines every build task declaratively. In Bazel, a task is called a target.
Each target declaration includes its build type, inputs, build method, outputs, dependencies, and so on. Here are two build tasks:
# Declare a jar to be used as a library by other tasks
java_library(
name = "greeter",
srcs = ["src/main/java/com/example/Greeting.java"],
)
# Declare an executable jar
java_binary(
name = "ProjectRunner",
srcs = ["src/main/java/com/example/ProjectRunner.java"],
main_class = "com.example.ProjectRunner",
# Depend on the library built earlier — this is the key to incremental builds
deps = [":greeter"],
)
At runtime, Bazel builds an internal directed dependency graph from the target declarations, like this:

With this directed graph, Bazel can do incremental builds.
When you modify Greeting.java, Bazel knows the //:greeter target depends on it, so Bazel knows it must rebuild //:greeter. And because //:ProjectRunner depends on //:greeter, Bazel knows it must rebuild //:ProjectRunner too.
That’s incremental build within a single language. Now let’s see how Bazel does it across multiple languages.
How Bazel does incremental builds across languages
In the project below, several technologies are used at once: Docker, Python, YAML, C++, and so on.

These dependencies were defined by the developers and operators as they wrote the code. So Bazel has the dependency graph from the very start.
Bazel lets you declare dependencies between targets of different languages, so naturally a project’s complete dependency graph emerges — you don’t have to spend extra effort collecting it.
When you run a Bazel build, Bazel notices that config.yaml was modified and computes which builds to run next — the path marked orange below: every direct and indirect dependent of //:config.yaml.
But because this is a build, Bazel only builds the source code along that path; it does not run the *_test test tasks.

This is precise build — no, incremental build: build only what needs building.
Curious how Bazel pulls this off? I’ll dig into Bazel’s internals in a future post.
How Bazel does precise testing
Bazel has many subcommands. Two common ones are build and test. These distinguish the kind of build, because sometimes you only want to build, not test.
Continuing the example, we again modify config.yaml, but this time we run the test subcommand. Bazel computes the same path as before — because the dependency scope affected by //:config.yaml is the same.
The difference is that this time, in addition to building, it runs the *_test tasks. Bazel doesn’t care whether a test is a unit test or an integration test; it only cares about the test’s size. That’s the part marked black below:
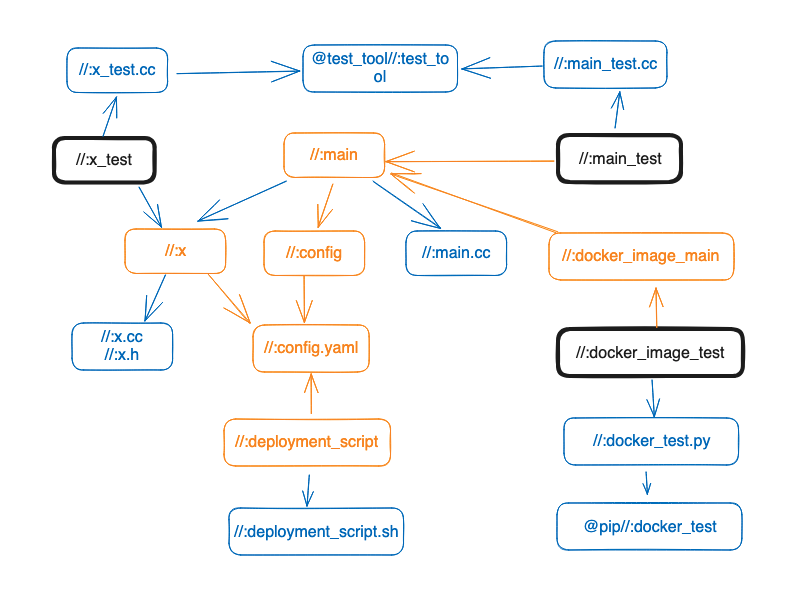
And that is precise testing. On top of this, Bazel notices that //:x_test, //:main_test, and //:docker_image_test are completely independent tests, so it can run them in parallel — speeding testing up further.
Precise testing is a byproduct of incremental builds
Recall the three steps of precise testing we summarized earlier:
- Find the change.
- From the change, find the related test cases.
- Run only those related test cases.
All of these steps can be done by Bazel — and done locally.
So with Bazel, implementing precise testing means you don’t have to invest in your own R&D to support multiple languages, and you certainly don’t have to build a pile of platforms.
But these benefits don’t come for free.
The cost of incremental builds (precise testing)
By now some readers will have noticed that the example above is a monorepo — all the code (front end, back end, ops, mobile) lives in a single repository.
That is one prerequisite for incremental builds.
The second prerequisite: you must use a tool like Bazel that supports incremental builds, which means existing projects may need to migrate their build tooling. And tools like Bazel still have low adoption across the industry, so rolling them out inside a company carries a real cost.
So — would you choose to implement precise testing on top of Bazel?